ボトムアップマルチエージェント強化学習
マルチエージェントシステム?
たとえば,倉庫内で複数のロボットが協調して荷物を運搬するシステムや惑星上でそれぞれの機能を持つロボットたちが協力して効率的な探査を行うシステムなど,複数のロボットが同じ環境で動作するようなシステムが実世界のさまざまな場面で求められています.
そのようなシステムを「マルチエージェントシステム」とよび,1台のエージェントの高性能化では解決の難しいタスクに対して限られた能力を持つ複数のエージェントを相互作用させることにより解決を目指します.
マルチエージェント強化学習?
マルチエージェントシステムを活用することで高度なタスクの実現が図れるという事実は,従来よりさまざまな実験により示されてきました. しかしながら,エージェント同士の相互作用から構成される集団行動をどう設計すればタスクが解決できるのか,という問題への答えは必ずしも自明ではありません. たとえば,惑星探査のように未知の環境で動作するマルチエージェントシステムの集団行動をあらかじめ設計することは困難です. また,大規模なマルチエージェントシステムに対して個別のロボットの動作を設計することは設計者にとって大きな負担となり,実質的に不可能な場合もありえます.
そのような問題に対し,強化学習とよばれる,報酬をもとにエージェントが方策を学習する機械学習手法を利用することで,マルチエージェントシステム自身に集団行動を学習させることを目指す枠組みが「マルチエージェント強化学習」です.
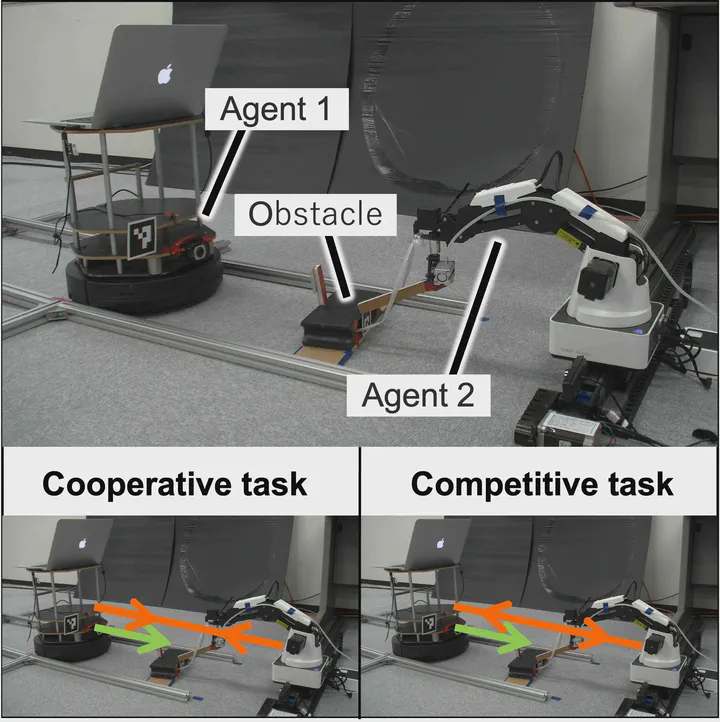
この研究の目的とこれまでの成果
従来のマルチエージェント強化学習では,マルチエージェントシステムに対して共通のタスクを設定し,全体を監視する中央集権的なシステムが各エージェントの貢献に応じて報酬を分配するという手法が主流です. この研究では,そのような「トップダウン」的な枠組みから脱却し,より自律性・分散性の高いマルチエージェント強化学習の実現を目指します. 具体的には,マルチエージェントシステム内の各エージェントが個別のタスクを持ち,中央集権型システムを排除した枠組みでの方策学習を開発しています. 各エージェントが個別のタスクを持つ場合であっても,マルチエージェントシステムの本来の目的であるはずの集団行動の達成は欠かすことができません. 私たちは,これまでに他のエージェントのタスクを考慮して,協調可能なエージェントとは協調し,競争関係にあるエージェントには打ち勝つような学習用の報酬を各エージェント自身が生成するためのアルゴリズムを提案してきました. 提案手法をいくつかのシミュレーシュンや実ロボットに適用することで,その有効性を示してきました.
[業績1] T. Aotani, T. Kobayashi and K. Sugimoto, “Bottom-up multi-agent reinforcement learning by reward shaping for cooperative-competitive tasks,” Applied Intelligence, 2021.
[業績2] T. Aotani, T. Kobayashi and K. Sugimoto, “Bottom-up multi-agent reinforcement learning for selective cooperation,” IEEE SMC, 2018.
青谷 拓海
助教
My research interests include multi-agent reinforcement learning and safe reinforcement learning for autonomous robots.