バイアス・バリアンスのトレードオフのメタ最適化
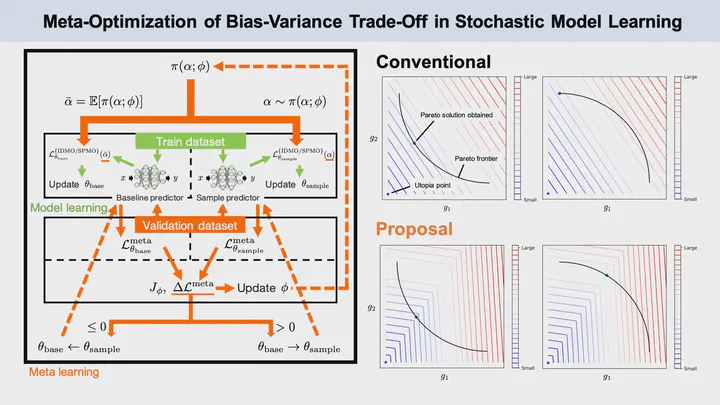
Model-based reinforcement learning is expected to be a method that can safely acquire the optimal policy under real-world conditions by using a stochastic dynamics model for planning. Since the stochastic dynamics model of the real world is generally unknown, a method for learning from state transition data is necessary. However, model learning suffers from the problem of bias-variance trade-off. Conventional model learning can be formulated as a minimization problem of expected loss. Failure to consider higher-order statistics for loss would lead to fatal errors in long-term model prediction. Although various methods have been proposed to explicitly handle bias and variance, this paper first formulates a new loss function, especially for sequential training of the deep neural networks. To explicitly consider the bias-variance trade-off, a new multi-objective optimization problem with the augmented weighted Tchebycheff scalarization, is proposed. In this problem, the bias-variance trade-off can be balanced by adjusting a weight hyperparameter, although its optimal value is task-dependent and unknown. We additionally propose a general-purpose and efficient meta-optimization method for hyperparameter(s). According to the validation result on each epoch, the proposed meta-optimization can adjust the hyperparameter(s) towards the preferred solution simultaneously with model learning. In our case, the proposed meta-optimization enables the bias-variance trade-off to be balanced for maximizing the long-term prediction ability. Actually, the proposed method was applied to two simulation environments with uncertainty, and the numerical results showed that the well-balanced bias and variance of the stochastic model suitable for the long-term prediction can be achieved.
青谷 拓海
助教
My research interests include multi-agent reinforcement learning and safe reinforcement learning for autonomous robots.